Objectives of Experiments
R is more and more popular in various fields, including the high-performance analytics and computing (HPAC) fields. Nowadays, the architecture of HPC system can be classified as pure CPU system, CPU + Accelerators (GPGPU/FPGA) heterogeneous system, CPU + Coprocessors system. In software side, high performance scientific libraries, such as basic linear algebra subprograms (BLAS), will significantly influence the performance of R for HPAC applications. So, in the first post of R benchmark series, the experiments mainly contain two aspects: (1) Performance on different architectures of HPC system, (2) Performance on different BLAS libraries.
Benchmark and Testing Goals
In this post, we choose R-25 benchmark (available in here ) which includes the most popular, widely acknowledged functions in the high performance analytic field. The testing script includes fifteen common computational intensive tasks (in Table-1) grouped into three categories: (1) Matrix Calculation (1-5) (2) Matrix function (6-10) (3) Programmation (11-15)
Table-1 R-25 Benchmark Description
Task Number
R-25 Benchmark Description
1 Creation,transposition,deformation of a 2500*2500 matrix
2 2400*2400 normal distributed random matrix
3 Sorting of 7,000,000 random values
4 2800*2800 cross-product matrix
5 Linear regression over a 3000*3000 matrix
6 FFT over 2,400,000 random values
7 Eigenvalues of a 640*640 random values
8 Determinant of a 2500*2500 random matrix
9 Cholesky decomposition of a 3000*3000 matrix
10 Inverse of a 1600*1600 random matrix
11 3,500,000 Fibonacci numbers calculation(vector calculation)
12 Creation of a 3000*3000 Hilbert matrix(matrix calculation)
13 Grand common divisors of 400,000 pairs(recursion)
14 Creation of a 500*500 Toeplitz matrix(loops)
15 Escoufier’s method on a 45*45 matrix(mixed)
In our benchmark, we measured the performance of R-25 benchmark on various hardware platforms, including Intel Xeon CPU processors, NVIDIA GPGPU cards and Intel Xeon Phi coprocessors. Meanwhile, R built with different BLAS libraries results in different performance, so we tested R with self-contained BLAS, OpenBLAS, Intel MKL and CUDA BLAS. Because the performance of self-contained BLAS is hugely** lower than the other BLAS library and in practice HPAC users of R always built R with high performance BLAS, the testing results running with self-contained BLAS is negligible. ** Moreover, in order to investigate the performance of functions or algorithms such as GEMM that HPC users mostly used, we explore the speed-up when varying the size of the matrices and number of elements as known as scalability.
System Descriptions
To evaluate the applicability of different methods for improving R performance in a HPC environment, the hardware and software of platform we used listed in the Table-2 and Table-3. 
Results and Discussions
(1) General Comparisons
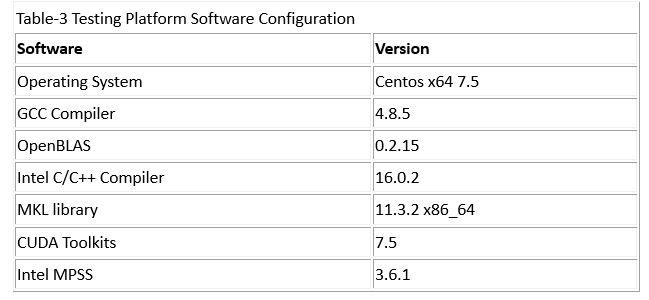
Fig. 1 shows the speedup of R using different BLAS libraries and different hosts. The default R running with OpenBLAS is shown in red as our baseline for comparison so that its speedup is constantly equal to one. Intel Xeon E5-2670 has eight physical cores in one chipset, so there are 16 physical cores in one server node.Intel MKL library supports the single thread mode (Sequential) or OpenMP threading mode. MKL with OpenMP threading mode defaultly uses all physical cores in one node(here is 16).Fig.1 shows the results of using Intel MKL for 1 thread and 16 threads with automatic parallel execution are shown in blue. There are five subtasks showing a significant benefit from either optimized sequential math library or the automatic parallelization with MKL including crossprod (matrix size 2800*2800), linear regression, matrix decomposition, computing inverse and determinant of a matrix. Other non-computational intensive tasks received very little performance gains from parallel execution with MKL. 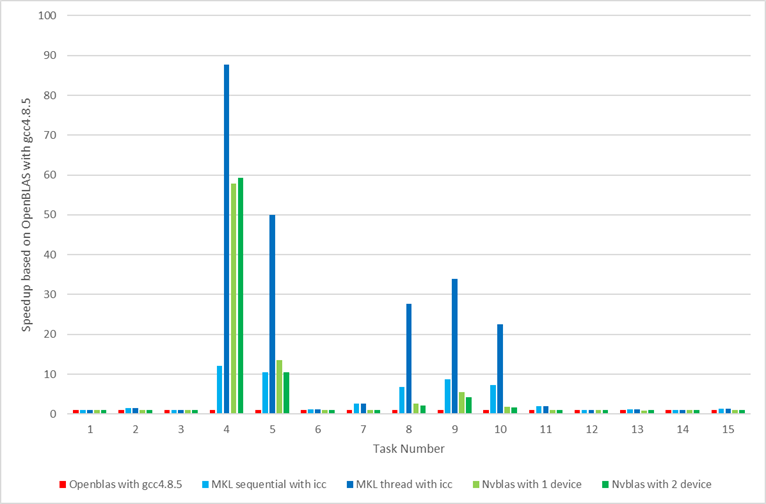
Fig.1 Performance comparison among Intel MKL and NVIDIA BLAS against R+OpenBLAS
We also exploited parallelism with CUDA BLAS (libnvblas.so) on NVIDIA GPU platform. Since drop-in library (nvblas) only accelerated the level 3 BLAS functions and overhead of preloading, the result (green column) in Fig.2 showed little benefit and even worse performance for some computing tasks against Intel MKL accelerations.
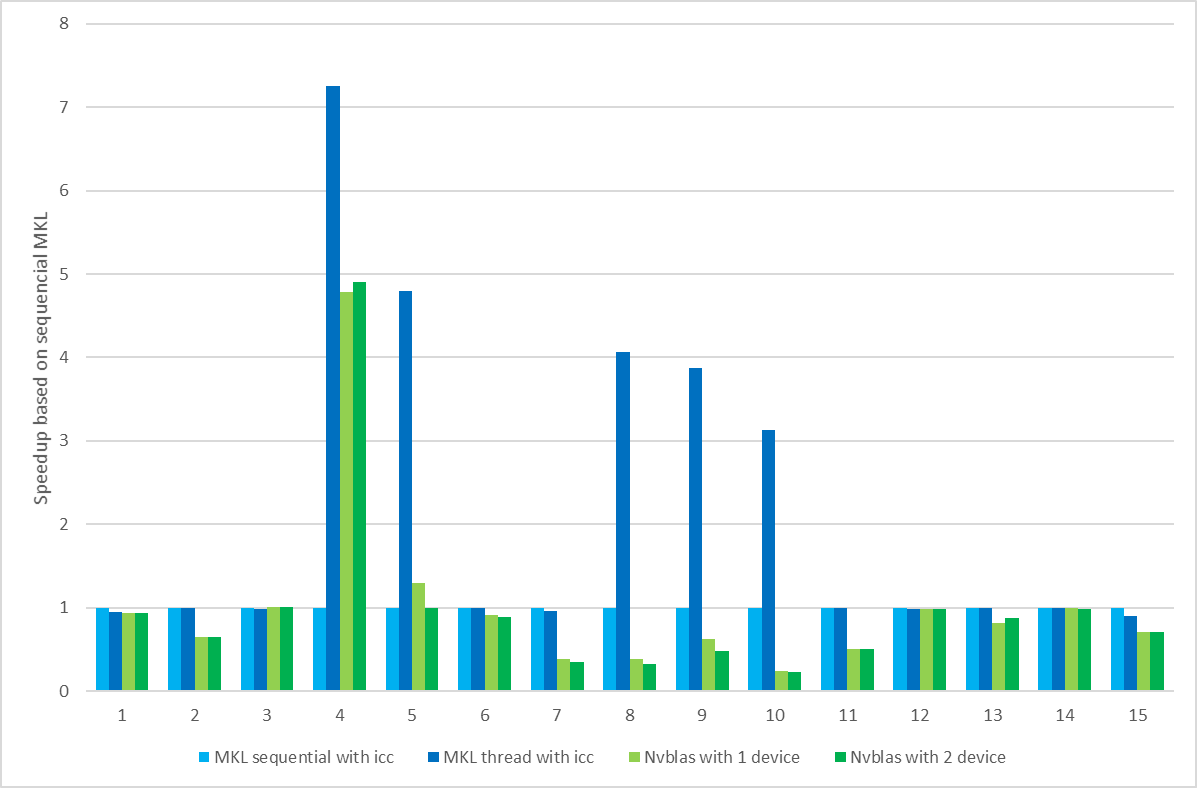
Fig.2 Performance comparison for CPU and GPU with NVIDIA BLAS and Intel MKL
(2) Scalability on NVIDIA GPU
The performance using two GPU devices (green column) is not superior to using one GPU device (blue column) , even the results of some subtasks on one GPU device gains more. Taking the function crossproduct with computing-intensive as an example is to explain the difference between one GPU device and two GPU device, as followed the Fig. 3. The advantage of the performance of the two card is gradually displayed as the size of the matrix increases. The sub-vertical axis shows the ratio of the elapsed time on two devices to one device. A ratio greater than 1 indicates that the two card performance is better than 1 cards,and the greater the ratio of the two cards, the better the performance of the card.
 Fig.3 Scalability for 1X and 2X NVIDIA K40m GPU for ‘crossprod’ function
Fig.3 Scalability for 1X and 2X NVIDIA K40m GPU for ‘crossprod’ function
(3) Heterogeneous Parallel Models on Intel Xeon Phi (MIC)
To compare the parallelism supported by pure CPU (Intel Xeon processor) and Intel Xeon Phi coprocessor, we conducted batch runs ( 10 times for the average elapsed time) with the different matrix size of matrix production. MKL supports automatic offload computation to Intel Xeon Phi card, but before using you must know , Automatic offload functions in MKL
- Level-3 BLAS: GEMM, TRSM, TRMM, SYMM
- LAPACK 3 amigos : LU, QR, Cholesky
Matrix size for offloading
- GEMM: M, N >2048, K>256
- SYMM: M, N >2048
- TRSM/TRMM: M, N >3072
- LU: M, N>8192
Here, we use **a%*%a** substituted for the function `crossprod` used in R-benchmark-25.R because _crossprod_ can not be auto-offloaded to Intel Xeon Phi. We compared the elapsed time running on CPU+Xeon Phi with running on pure CPU. In Fig.4, the vertical axis is the ratio of running elapsed time with CPU+Xeon Phi running mode to elapsed time with pure CPU running mode. The results showed the greater size of the matrix, the better performance CPU+Xeon Phi gains. The matrix size less than 4000 could get the best performance on pure CPU.
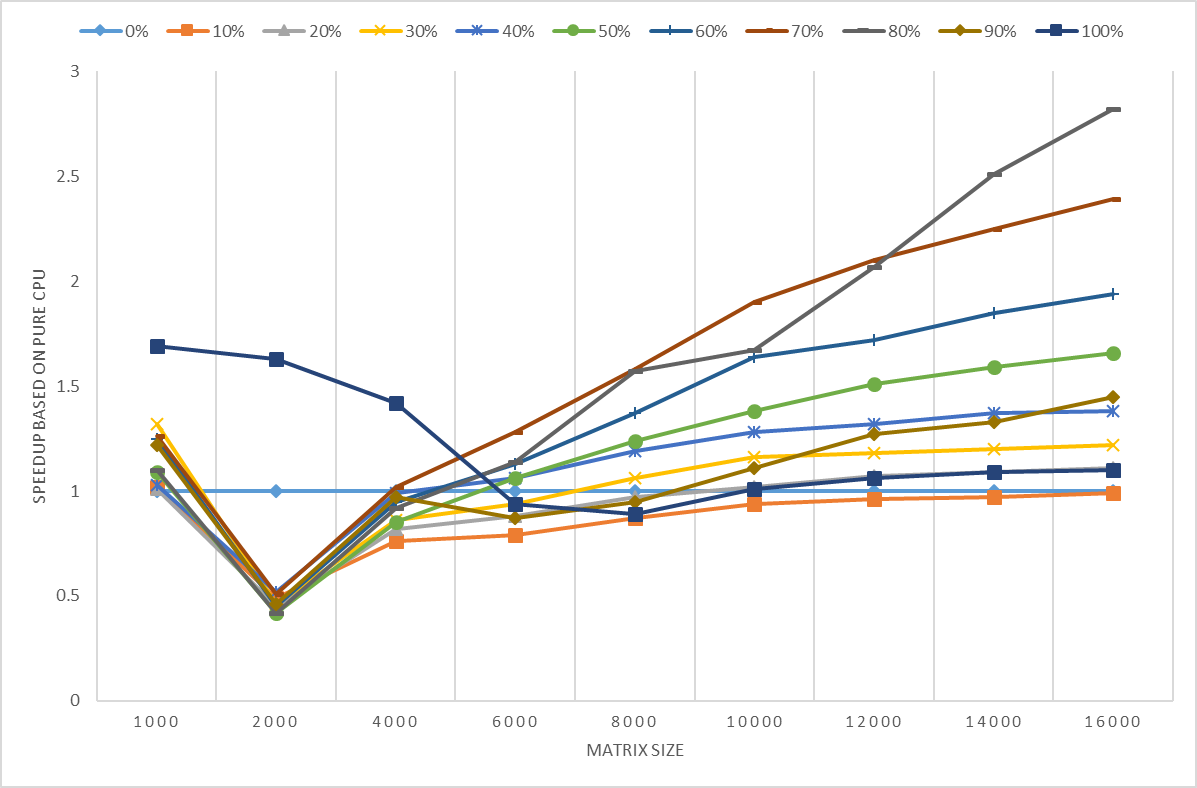
Fig.4 Heterogeneous Computing with Intel Xeon and Intel Xeon Phi
Fig.5 shows the 80% computation on Xeon Phi could get the best performance as the matrix size is growing, 70% computation on Xeon Phi could get the steadily better performance when the matrix size larger than 2000. 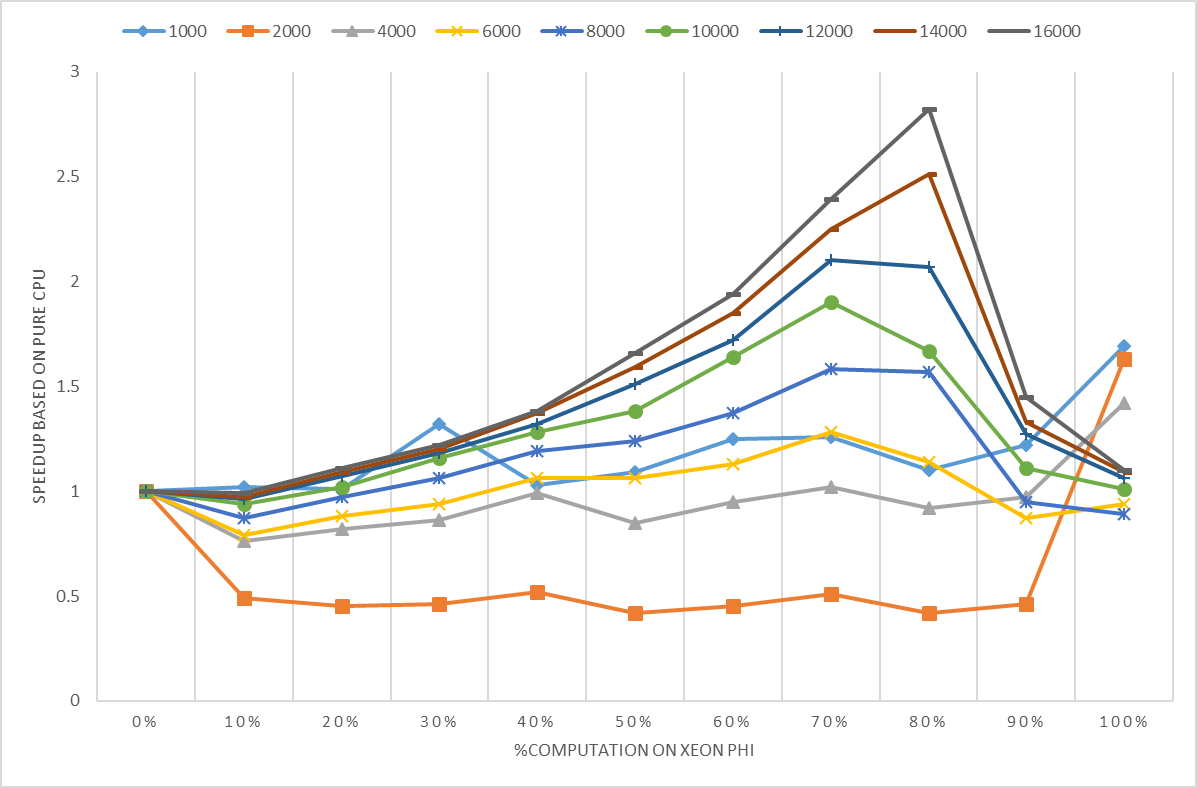
Fig.5 Different computation ratio on Intel Xeon Phi result in different performance
(4) Comparison NVIDIA GPU with Intel Xeon Phi
Here, we plotted the results of NVIDIA GPU and Intel Xeon Phi compared to Intel Xeon in Fig.6. In general, 80% running on Xeon Phi(2X 7110P)+Xeon CPU(2X E5-2670) gets similar performance to 1X K40m+2X E5-2670(2X 7110P ~ 1X K40m). When the matrix size is less than 12000, GPU gets better performance than Xeon Phi. And after that, Intel Xeon Phi shows the similar performance with NVIDIA K40m. For this benchmark, it can clearly seen that NVIDIA’s Tesla GPU(2X K40m) outperforms significantly.At 16000 of matrix size, nearly 3.9x faster than the 8-core dual E5-2670(Sandy-Bridge CPU) and 2.3x faster than the 80% running on Xeon Phi. The Xeon Phi is 2.8x faster than the Sandy-Bridge.
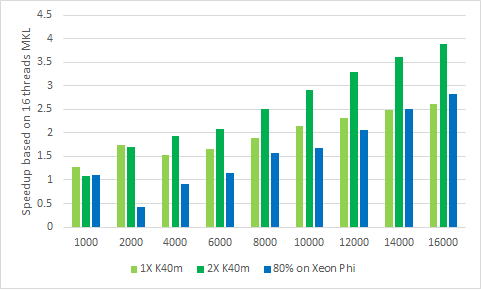
Fig.6 Comparison NVIDIA GPU with Intel Xeon Phi
Conclusions
In this article, we tested the R-benchmark-25.R script on the different hardware platform with different BLAS libraries. From our analysis, we concluded (1) R built with Intel MKL (either sequential or threaded) can accelerate lots of computationally intensive algorithms of HPAC and get the best performance, such as linear regression, PCA, SVD (2) R is performed faster on GPU for matrix production (GEMM) since it’s really computational intensive algorithm and GPU has more computing cores than Intel Xeon or Xeon Phi (3) R executed in the heterogeneous platforms (CPU+GPU or CPU+MIC) can gain more performance improvements (4) R can get more benefits from multiple GPUs, especially for large GEMM operations. In the next post, we will further investigate the benchmark performance with different R parallel packages and commercial productions of R .
Appendix : How to build R with different BLAS library
STOCK R
(1) Stock R build
Download base R package from the R project website, the current package is R-3.2.3.
Enter into the R root directory, and execute
$./configure –with-readline=no –with-x=no –prefix=$HOME/R-3.2.3-ori
$make -j4
$make install
(2) Add R bin directory and library directory to the environment variables PATH and LD_LIBRARY_PATH seperately, just like as:
export PATH=$HOME/R-3.2.3-ori/bin:$PATH
export LD_LIBRARY_PATH=$HOME/R-3.2.3-ori/lib64/R/lib:$LD_LIBRARY_PATH
R WITH OPENBLAS
(1) OpenBLAS build
Download OpenBlas-0.2.15.tar.gz from http://www.openblas.net/
Change directory to OpenBLAS Home directory, and execute
$make
$make PREFIX=$OPENBLAS_INSTALL_DIRECTORY install
(2) Set the OpenBLAS library environment
(3) Run benchmark
$LD_PRELOAD=$OPENBLAS_HOME/lib/libopenblas.so R
R WITH INTEL MKL
(1)Obtain Intel parallel studio software from Intel website
(2) Install the parallel studio
(3) Set the Intel compiler and MKL library environment
(4) Build R with MKL
Link MKL libraries configuration file mkl.conf as follows:
a. Sequencial MKL or MKL single thread
#make sure intel compiler is installed and loaded which can be set in .bashrc
as e.g.
source /opt/intel/bin/compilervars.sh intel64
MKL_LIB_PATH=/opt/intel/mkl/lib/intel64## Use intel compiler
CC=’icc -std=c99′
CFLAGS=’-g -O3 -wd188 -ip ‘F77=’ifort’
FFLAGS=’-g -O3 ‘CXX=’icpc’
CXXFLAGS=’-g -O3 ‘FC=’ifort’
FCFLAGS=’-g -O3 ‘## MKL sequential, ICC
MKL=” -L${MKL_LIB_PATH}
-Wl,–start-group
-lmkl_intel_lp64
-lmkl_sequential
-lmkl_core
-Wl,–end-group”
b. OpenMP Threading MKL
#make sure intel compiler is installed and loaded which can be set in .bashrc
as e.g.
source /opt/intel/bin/compilervars.sh intel64
MKL_LIB_PATH=/opt/intel/mkl/lib/intel64## Use intel compiler
CC=’icc -std=c99′
CFLAGS=’-g -O3 -wd188 -ip ‘F77=’ifort’
FFLAGS=’-g -O3 ‘CXX=’icpc’
CXXFLAGS=’-g -O3 ‘FC=’ifort’
FCFLAGS=’-g -O3 ‘## MKL With Intel MP threaded , ICC
MKL=” -L${MKL_LIB_PATH}
-Wl,–start-group
-lmkl_intel_lp64
-lmkl_intel_thread
-lmkl_core
-Wl,–end-group
-liomp5 -lpthread”
build R with following command,
$./configure –prefix=$HOME/R-3.2.3-mkl-icc –with-readline=no –with-x=no –with-blas=”$MKL” –with-lapack CC=’icc -std=c99′ CFLAGS=’-g -O3 -wd188 -ip ‘ F77=’ifort’ FFLAGS=’-g -O3 ‘ CXX=’icpc’ CXXFLAGS=’-g -O3 ‘ FC=’ifort’ FCFLAGS=’-g -O3 ‘
$make -j 4; make install
(5) Set $HOME/R-3.2.3-mkl-icc environment
R WITH CUDA BLAS
(1) Install the driver and CUDA tools with version up to 6.5 for NVIDIA Tesla Cards
(2)Set the CUDA environment
(3)Edit the nvblas.conf file
1 | # This is the configuration file to use NVBLAS Library |
Set NVBLAS_CONFIG_FILE to the nvblas.conf location
(4) Run the benchmark
LD_PRELOAD=/opt/cuda-7.5/lib64/libnvblas.so R
R WITH MKL ON INTEL XEON PHI
(1) Build R with MKL
Build R with MKL is same to Threaded MKL at 6
(2) Enable MKL MIC Automatic Offload Mode
export MKL_MIC_ENABLE=1
export MIC_KMP_AFFINITY=compact
Otherwise , you can set the workload division between host CPU and MIC card. If one host has two MIC cards, you could set:
export MKL_HOST_WORKDIVISION=0.2
export MKL_MIC_0_WORKDIVISION=0.4
export MKL_MIC_1_WORKDIVISION=0.4