XGBoost is a comprehensive machine learning library for gradient boosting. It began from the Kaggle community for online machine learning challenges, and then maintained by the collaborative efforts from the developers in the community. It is well known for its accuracy, efficiency and flexibility for various interfaces: the computational module is implemented in C++, and currently provides interfaces for R, python, Julia and Java. Its corresponding R package, xgboost, in this sense is non-typical in terms of the design and structure. Although it is common that an R package is a wrapper of another tool, not many packages have the backend supporting many ways of parallel computation. The structure of the Project can be illustrated as follows: 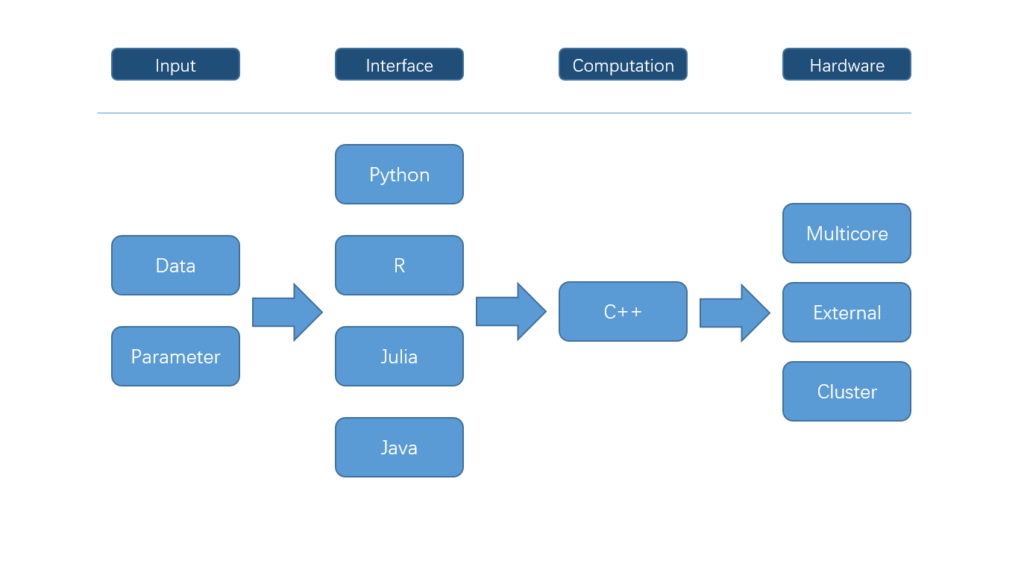 Although it is common that an R package is a wrapper of another tool, not many packages have the backend supporting many ways of parallel computation. In xgboost, most works are done in the C++ part in the above Figure. Since all interfaces share the same computational backend, there is not really a difference in terms of the accuracy or efficiency of the results from different interfaces. Users only need to prepare the data and parameters in the preferred language, then call the corresponding interface and wait for the training and prediction. This design puts most heavy works to the background, and only asks for the minimum support from each interface. For this reason, we can expect in the future there will be more languages wrapping the XGBoost backend and their users can enjoy the parallel training power. XGBoost implements a gradient boosting trees algorithm. A gradient boosting trees model trains a lot of decision trees or regression trees in a sequence, where only one tree is added to the model at a time, and every new tree depends on the previous trees. This nature limits the level of parallel computation, since we cannot build multiple trees simultaneously. Therefore, the parallel computation is introduced in a lower level, i.e. in the tree-building process at each step.
Although it is common that an R package is a wrapper of another tool, not many packages have the backend supporting many ways of parallel computation. In xgboost, most works are done in the C++ part in the above Figure. Since all interfaces share the same computational backend, there is not really a difference in terms of the accuracy or efficiency of the results from different interfaces. Users only need to prepare the data and parameters in the preferred language, then call the corresponding interface and wait for the training and prediction. This design puts most heavy works to the background, and only asks for the minimum support from each interface. For this reason, we can expect in the future there will be more languages wrapping the XGBoost backend and their users can enjoy the parallel training power. XGBoost implements a gradient boosting trees algorithm. A gradient boosting trees model trains a lot of decision trees or regression trees in a sequence, where only one tree is added to the model at a time, and every new tree depends on the previous trees. This nature limits the level of parallel computation, since we cannot build multiple trees simultaneously. Therefore, the parallel computation is introduced in a lower level, i.e. in the tree-building process at each step.  Specifically, the parallel computation takes place in the operation where the model scans through all features on each internal node and set a threshold. Say we have a 4-core CPU for the training computation, then XGBoost separate the features into 4 groups. For the splitting operation on a node, XGBoost distributes the operation on each feature to their corresponding core. The training data is stored in a piece of shared memory, each core only needs to access one group of features, and perform the computation individually. The implementation is done in C++ with the help of OpenMP. It is obvious that users can benefit fully from the parallel computation if the number of features is larger than the number of threads of the CPU. XGBoost also supports training on a cluster, or with external memory. We will briefly introduce them in the following parts.
Specifically, the parallel computation takes place in the operation where the model scans through all features on each internal node and set a threshold. Say we have a 4-core CPU for the training computation, then XGBoost separate the features into 4 groups. For the splitting operation on a node, XGBoost distributes the operation on each feature to their corresponding core. The training data is stored in a piece of shared memory, each core only needs to access one group of features, and perform the computation individually. The implementation is done in C++ with the help of OpenMP. It is obvious that users can benefit fully from the parallel computation if the number of features is larger than the number of threads of the CPU. XGBoost also supports training on a cluster, or with external memory. We will briefly introduce them in the following parts.
In the following part, we will demonstrate the performance of the R package with different parallel strategies. We hope this introduction can be an example of a computational efficient R package.
1. Multi-threading on a single machine
XGBoost offers the option to parallel the training process in an implicit style on a single machine, which could be a workstation or even your own laptop. This is one of the reasons that the Kaggle community loves it. In R, the switch of multi-threading computation is just a parameter nthread:
1 | require(xgboost) |
In the results from the toy example, there is a noticeable difference between the one-thread and four-thread trainings. As a comparison, we made the following figure from a competition data(https://www.kaggle.com/c/higgs-boson/data) on Kaggle. The experiments were run on a laptop with an i7-4700m CPU. 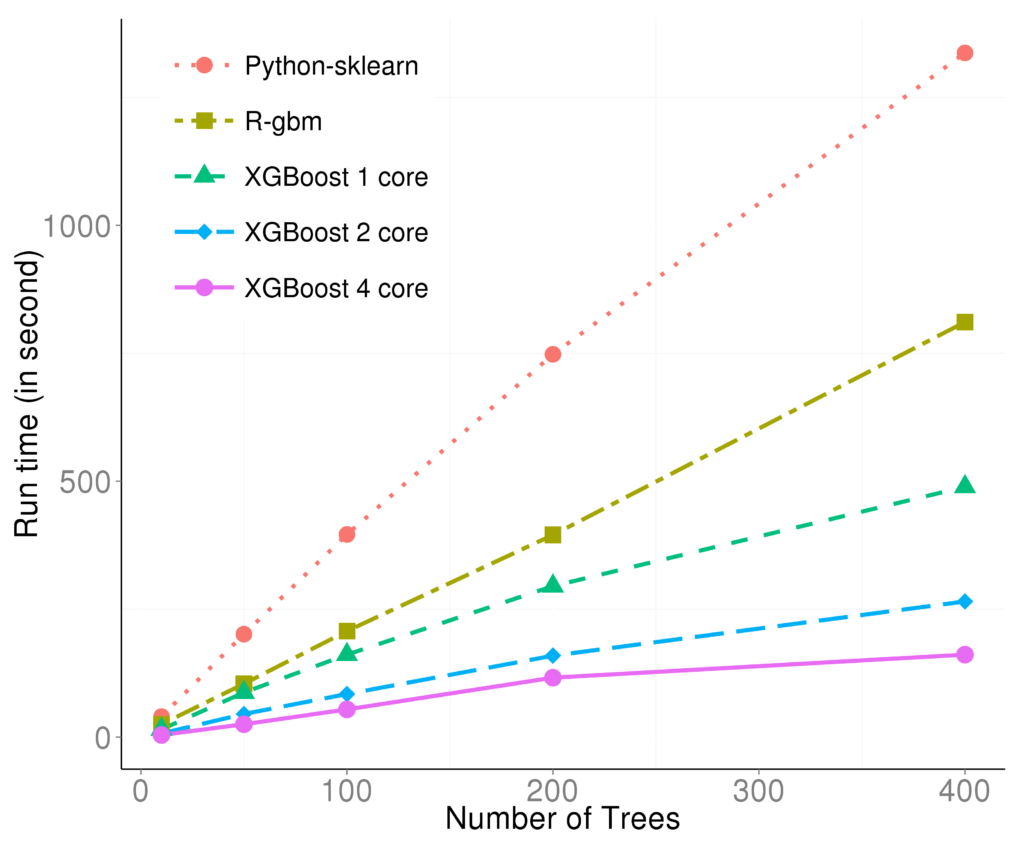 The marks R and python are the vanilla gradient boosting machine implementation. XGBoost is the fastest when using only one thread. By employing 4 threads the process can be almost 4x faster. To reproduce the above results, one can find related scripts at:https://github.com/dmlc/xgboost/tree/master/demo/kaggle-higgs. Note that the plot was made in 2015, thus the results may vary due to changes in the packages.
The marks R and python are the vanilla gradient boosting machine implementation. XGBoost is the fastest when using only one thread. By employing 4 threads the process can be almost 4x faster. To reproduce the above results, one can find related scripts at:https://github.com/dmlc/xgboost/tree/master/demo/kaggle-higgs. Note that the plot was made in 2015, thus the results may vary due to changes in the packages.
2. Parallel on a Cluster
For some cases where the size of data is too large to fit into the memory, people may set up a cluster to parallel the training process. However, a uniformed API of multi-nodes parallel computation for different interface languages is still left to be developed. The current standard way to parallel the training is to use the C++ backend with a configuration file which manages the model parameters and then submit it to Yarn. For further information, please read the official documentation: http://xgboost.readthedocs.io/en/latest/tutorials/aws_yarn.html. It is also possible to distribute the computation in one’s own cluster, but there’s no documentation provided yet. One thing worth noticing is that when performing multi-node parallel computation, the data is split by the rows, thus on each node it is (almost) impossible to search for the exact best splitting point. As a result, XGBoost switches to an approximate algorithm mentioned in this paper. Briefly speaking, the approximate algorithm creates a histogram to represent each feature based on its numerial distribution. It reduces the amount of calculation on slaves, makes the reduce step easier, and maintains the precision at the same time.
3. External Memory
External memory is a compromise of large size of input and insufficient computational resources. The basic idea is simple: store the input data on an SSD, which is cheaper than memory and faster than HDD, and repeatedly load a chunk of data into memory to train the model partially. Comparing to the parallel training on a cluster, this strategy also uses the approximate algorithm, but is more convenient to configure and call, and is also cheaper for most users. To enable the external memory for R, we need to make sure that the compiler on your machine supports it. Usually it is fine with the latest gcc/clang. For windows users with mingw, however, is not able to try it out. The data files also need to be in the libsvm format on the disk. Files used in this demo can be downloaded at https://github.com/dmlc/xgboost/tree/master/demo/data. Here’s the usual way to load the data into memory with xgboost’s own data structure:
1 | dtrain = xgb.DMatrix('agaricus.txt.train') |
Now if we add the suffix:
1 | dtrain = xgb.DMatrix('agaricus.txt.train#train.cache') |
Note the only difference is just the suffix: A “#” and the string following. The suffix can be arbitrary string as the prefix of the generated cache files, as printed in the output. With the suffix, the function automatically marks the file for external memory training. In the external memory mode we can also perform multi-threading training for each chunk of data, because the chunks are taken into the training process in a linear relationship. More details are included in this paper.
Summary
XGBoost puts effort in the three popular parallel computation solutions, multithreading, distributed parallel and out-of-cores computations. The idea of this project is to only expose necessary APIs for different language interface design, and hide most computational details in the backend. So far the library is fast and user-friendly, we wish it could inspire more R package developers to balance the design and efficiency. The development will be continued, and contributions on code and ideas are always welcome :)