Introduction
GPUs (Graphic Processing Units) have become much more popular in recent years for computationally intensive calculations. Despite these gains, the use of this hardware has been very limited in the R programming language. Although possible, the prospect of programming in either OpenCL or CUDA is difficult for many programmers unaccustomed to working with such a low-level interface. Creating bindings for R’s high-level programming that abstracts away the complex GPU code would make using GPUs far more accessible to R users. This is the core idea behind the gpuR package. There are three novel aspects of gpuR:
- Applicable on ‘ALL’ GPUs
- Abstracts away CUDA/OpenCL code to easily incorporate in to existing R algorithms
- Separates copy/compute functions to allow objects to persist on GPU
Broad application:
The ‘gpuR’ package was created to bring the power of GPU computing to any R user with a GPU device. Although there are a handful of packages that provide some GPU capability (e.g. gputools, cudaBayesreg, HiPLARM, HiPLARb, and gmatrix) all are strictly limited to NVIDIA GPUs. As such, a backend that is based upon OpenCL would allow all users to benefit from GPU hardware. The ‘gpuR’ package therefore utilizes the ViennaCL linear algebra library which contains auto-tuned OpenCL kernels (among others) that can be leveraged for GPUs. The headers have been conveniently repackaged in the RViennaCL package. It also allows for a CUDA backend for those with NVIDIA GPUs that may see further improved performance (contained within the companion gpuRcuda package not yet formally released).
Abstract away GPU code:
The gpuR package uses the S4 object oriented system to have explicit classes and methods that all the user to simply cast their matrix or vector and continue programming in R as normal. For example:
1 | ORDER = 1024 |
The gpuMatrix object points to a matrix in RAM which is then computed by the GPU when a desired function is called. This avoids R’s habit of copying the memory of objects. For example:
1 | library(pryr) |
In contrast, the same syntax for a gpuMatrix will modify the original object in-place without any copy.
1 | library(pryr) |
Each new variable assigned to this object will only copy the pointer thereby making the program more memory efficient. However, the gpuMatrix> class does still require allocating GPU memory and copying data to device for each function call. The most commonly used methods have been overloaded such as %*%, +, -, *, /, crossprod, tcrossprod, and trig functions among others. In this way, an R user can create these objects and leverage GPU resources without the need to know a bunch more functions that would break existing algorithms.
Distinct Copy/Compute Functionality:
For the gpuMatix and gpuVector classes there are companion vclMatrix and vclVector class that point to objects that persist in the GPU RAM. In this way, the user explicitly decides when data needs to be moved back to the host. By avoiding unnecessary data transfer between host and device performance can significantly improve. For example:
1 | vclA = vclMatrix(rnorm(10000), nrow = 100) |
In this code, the three initial matrices already exist in the GPU memory so no data transfer takes place in the GEMM call. Furthermore, the returned matrix remains in the GPU memory. In this case, the ‘vclD’ object is still in GPU RAM. As such, the element-wise addition call also happens directly on the GPU with no data transfers. It is worth also noting that the user can still modify elements, rows, or columns with the exact same syntax as a normal R matrix.
1 | vclD[1,1] = 42 |
These operations simply copy the new elements to the GPU and modify the object in-place within the GPU memory. The ‘vclD’ object is never copied to the host.
Benchmarks:
With all that in mind, how does gpuR perform? Here are some general benchmarks of the popular GEMM operation. I currently only have access to a single NVIDIA GeForce GTX 970 for these simulations. Users should expect to see differences with high performance GPUs (e.g. AMD FirePro, NVIDIA Tesla, etc.). Speedup relative to CPU will also vary depending upon user hardware.
(1) Default dGEMM vs Base R
R is known to only support two numeric types (integer and double). As such, Figure 1 shows the fold speedup achieved by using the gpuMatrix and vclMatrix classes. Since R is already known to not be the fastest language, an implementation with the OpenBLAS backend is included as well for reference using a 4 core Intel i5-2500 CPU @ 3.30GHz. As can be seen there is a dramatic speedup from just using OpenBLAS or the gpuMatrix class (essentially equivalent). Of interest is the impact of the transfer time from host-device-host that is typical in many GPU implementations. This cost is eliminated by using the vclMatrix class which continues to scale with matrix size. [caption id=”attachment_768” align=”aligncenter” width=”640”]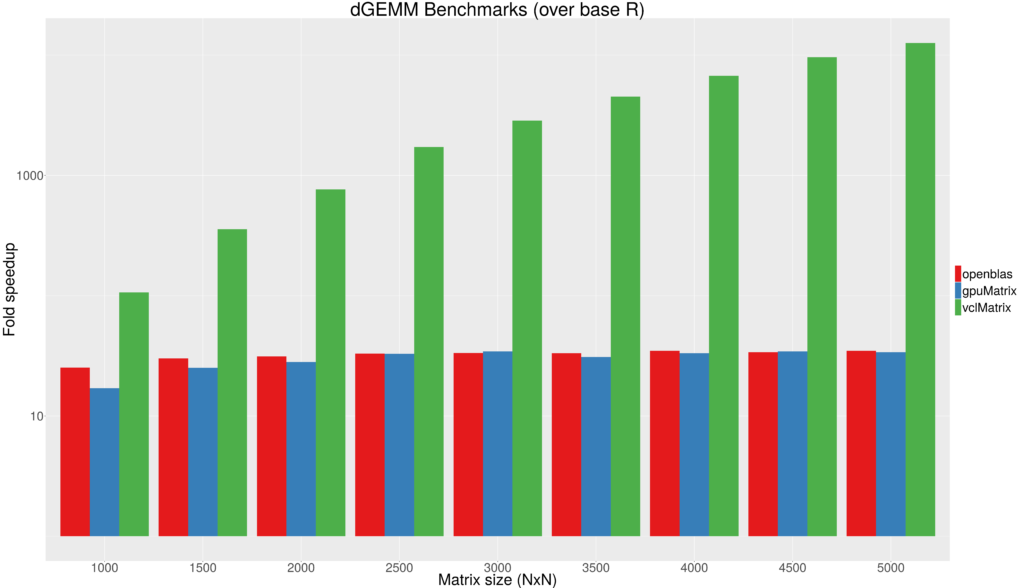 Figure 1 - Fold speedup achieved using openblas (CPU) as well as the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption]
Figure 1 - Fold speedup achieved using openblas (CPU) as well as the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption]
(2) sGEMM vs Base R
In many GPU benchmarks there is often float operations measured as well. As noted above, R does not provide this by default. One way to go around this is to use the RcppArmadillo or RcppEigen packages and explicitly casting R objects as float types. The armadillo library will also default to using the BLAS backend provided (i.e. OpenBLAS). Float types are implemented gpuR by setting type = "float" in the matrix calls (e.g. vclMatrix(mat, type = "float")) in Figure 2 shows the impact of using float data types. OpenBLAS continues to provide a noticeable speedup but gpuMatrix begins to outperform once matrix order exceeds 1500. The vclMatrix continues to demonstrate the value in retaining objects in GPU memory and avoiding memory transfers. [caption id=”attachment_769” align=”aligncenter” width=”640”]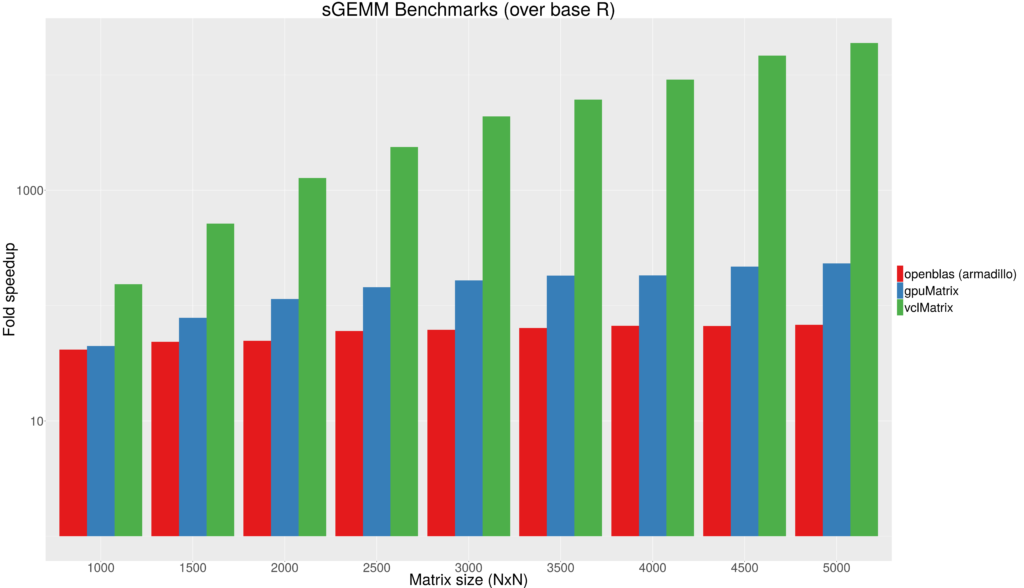 Figure 2 - Float type GEMM comparisons. Fold speedup achieved using openblas (via RcppArmadillo) as well as the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption] To give an additional view on the performance achieved by
Figure 2 - Float type GEMM comparisons. Fold speedup achieved using openblas (via RcppArmadillo) as well as the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption] To give an additional view on the performance achieved by gpuMatrix and vclMatrix is comparing directly against the OpenBLAS performance. The gpuMatrix reaches ~2-3 fold speedup over OpenBLAS whereas vclMatrix scales to over 100 fold speedup! It is curious as to why the performance with vclMatrix is so much faster (only differing in host-device-host transfers). Further optimization with gpuMatrix will need to be explored (fresh eyes are welcome) accepting limitations in the BUS transfer speed. Performance will certainly improve with improved hardware capabilities such as NVIDIA’s NVLink. [caption id=”attachment_831” align=”aligncenter” width=”737”]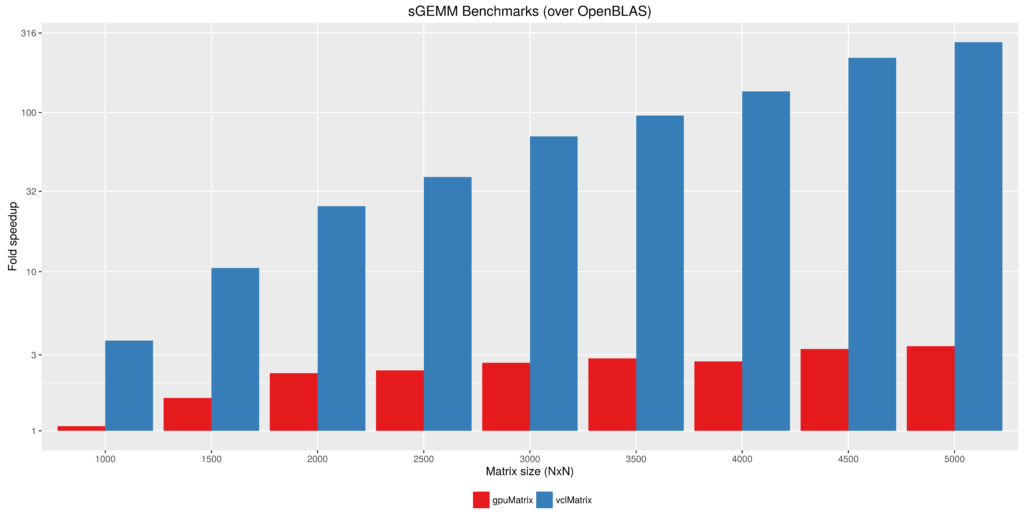 Figure 3 - Fold speedup achieved over openblas (via RcppArmadillo) float type GEMM comparisons vs the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption]
Figure 3 - Fold speedup achieved over openblas (via RcppArmadillo) float type GEMM comparisons vs the gpuMatrix/vclMatrix (GPU) classes provided in gpuR.[/caption]
Conclusion
The gpuR package has been created to bring GPU computing to as many R users as possible. It is the intention to use gpuR to more easily supplement current and future algorithms that could benefit from GPU acceleration. The gpuR package is currently available on CRAN. The development version can be found on my github in addition to existing issues and wiki pages (assisting primarily in installation). Future developments include solvers (e.g. QR, SVD, cholesky, etc.), scaling across multiple GPUs, ‘sparse’ class objects, and custom OpenCL kernels. As noted above, this package is intended to be used with a multitude of hardware and operating systems (it has been tested on Windows, Mac, and multiple Linux flavors). I only have access to a limited set of hardware (I can’t access every GPU, let along the most expensive). As such, the development of gpuR depends upon the R user community. Volunteers who possess different hardware are always welcomed and encouraged to submit issues regarding any discovered bugs. I have begun a gitter account for users to report on successful usage with alternate hardware. Suggestions and general conversation about gpuR is welcome.